
Dell Technologies has announced a joint initiative with NVIDIA to bring generative AI to enterprise customers.
The Dell Validated Design for Generative AI is a full-stack solution that enables enterprises to create and run custom AI models built with the knowledge of their business. We’ll get to the specifics of the announcement in this series but firstly lets set the stage.
What is Generative AI in simple terms?
Generative AI is a type of AI system capable of generating text, images, or other media in response to prompts. Generative models learn the patterns and structure of the input data, and then generate new content that is similar to the training data but with some degree of novelty.

The most prominent frameworks for approaching generative AI include generative adversarial networks (GANs) and generative pre-trained transformers (GPTs).
- GPTs are artificial neural networks that are based on the transformer architecture, pre-trained on large datasets of unlabeled text, and able to generate novel human-like text.
- GANs consist of two parts: a generator network that creates new data samples and a discriminator network that evaluates whether the samples are real or fake. (This series will not focus on GANs)
Generative AI has many potential applications, including in creative fields such as art, music, and writing, as well as in fields such as healthcare, finance, and gaming. We have all seen this in action with the release of Chat GPT and Bing Chat as of late.
Where do Large Language Models (LLMs) fit into the picture?
Glad you asked! GPTs (Generative Pre-trained Transformers) are a type of LLM (Large Language Model). The datasets used to train a GPT can come from a variety of sources, including internal documents, customer interactions, and publicly available information. The GPT will then use this data to learn the patterns and structure of the language, allowing it to generate new content that is similar to the training data.
GPTs are trained using large amounts of text data. In other words, LLMs are the outcome of training a model on large amounts of text data. A Large Language Model (LLM) consists of a neural network with many parameters (typically billions of weights or more), trained on large quantities of text using self-supervised learning or semi-supervised learning.

LLMs emerged around 2018 and have since become capable of performing well at a wide variety of tasks.
LLMs are general-purpose models which excel at a wide range of tasks, as opposed to being trained for one specific purpose. They demonstrate considerable general knowledge about the world and can “memorize” many facts during training.
How can LLM’s help businesses?
Artificial Intelligence (AI) will become integral to modern business operations and large Language Models (LLMs) have emerged as one of the most powerful types of AI models available today. With business cases ranging from conversational agents and chatbots for customer service, audio and visual content creation, software programming, security, fraud detection, threat intelligence, natural language interaction, and translation.
LLMs can help enable a myriad of new applications and business opportunities. Enterprise customers can (and will) use LLMs to empower their company’s business intelligence and unlock the value of AI in ways that were previously not possible.
There will be few areas of business and society that will not be impacted in some way by this technology.
Why should I consider developing my own LLM’s instead of using other services?
While public generative AI models such as ChatGPT, Google Bard AI, Microsoft Bing Chat, and a host of other and more specialized offerings are intriguing, you can’t download these GPT models and further train / fine tune them (they are not open / open source).
You can access these models through a few different means. For example OpenAI offers an API for developers to use the GPT model in their applications (Charged API model, tokens, embedding etc). Embeddings and Token (Words and the amount of them) are the means available in terms of further providing context to these models on your specific data.

Company’s such as OpenAI and Microsoft are starting to work with other companies to implement their GPT/LLM’s models on-prem with customers and this landscape is rapidly evolving, however, there is a compelling need for enterprises to develop their own Large Language Models (LLMs) that are trained on known data sets or developed or fine-tuned from known pre-trained models.
Benefits of developing own LLM – Iterate, Re-Train, Improve
Developing your own large language model as opposed to using an existing one can provide several commercial and business benefits. However, it’s important to note that creating a large language model from scratch requires resources and expertise. Here are some potential benefits:

- Customization and Optimization: Developing your own model allows you to train it on specific data to meet your unique business needs. You can tailor it to understand industry-specific jargon, customer interaction styles, or the nuances of your particular products and services.
- Data Security and Privacy: When you use a third-party model, you often need to send your data to the provider’s servers, which may raise privacy concerns. By developing your own model, you can keep your data in-house, enhancing data security and privacy.
- Control Over Updates and Maintenance: Owning the model means you control when and how to update it, allowing for quicker reactions to changing business needs or customer feedback.
- Competitive Advantage: A unique, effective language model can be a powerful tool that sets your business apart from competitors. It can improve the customer experience, drive efficiencies, and even become a product or service you can sell.
- Reduced Long-Term Costs: While the initial investment might be high, you could save money in the long run by not paying licensing or usage fees to a third-party provider.
- Intellectual Property: The algorithms, training data, and resulting models can become valuable intellectual property assets for your business.
What about a pre-trained model?
Training your own language model can give you greater control over the training data, as well as the ability to fine-tune the model for your specific needs. However, it can also be time-consuming and resource-intensive, as training a language model requires a significant amount of computing power and data.
On the other hand, using a pre-trained language model can save time and resources, as well as provide a strong foundation for your NLP tasks. Pre-trained language models, such as GPT-3 and BERT, have been trained on large amounts of high-quality data, and can be fine-tuned for specific tasks with smaller amounts of task-specific data. Additionally, pre-trained models often have a range of pre-built functionalities, such as sentence encoding and language translation, that can be readily used.
Ultimately, the decision to train your own language model or use a pre-trained one should be based on your specific needs and resources. If you have ample computing power and high-quality data that is specific to your use case, training your own language model may be the best choice. However, if you have limited resources or need a strong foundation for your NLP tasks, using a pre-trained language model may be the way to go.
How are Dell Technologies helping ?
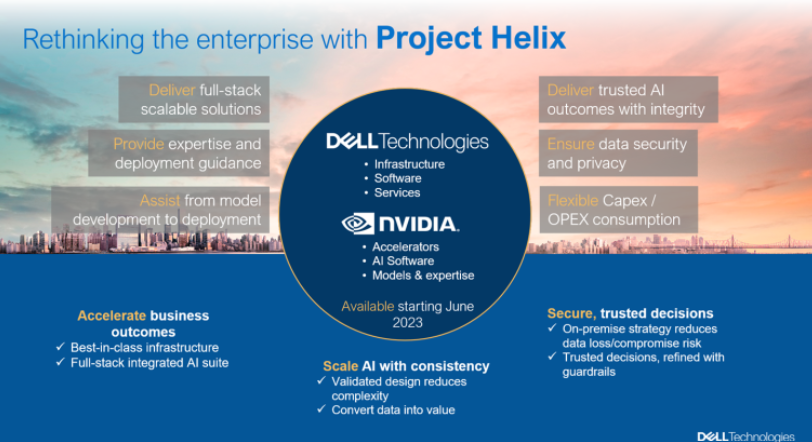
Dell and NVIDIA have already been leading the way in delivering joint innovations for artificial intelligence and high-performance computing and are actively collaborating in this new space to enable customers to create and operate Generative AI models for the Enterprise.
- Dell has industry-leading servers with NVIDIA compute and infrastructure accelerators, data storage systems, networking, management, reference designs, and the experience of helping numerous enterprises of all types and sizes with their AI and Infrastructure Solutions initiatives.
- NVIDIA has state-of-the-art, pre-trained foundation models, NVIDIA AI Enterprise software, system software to manage many networked systems simultaneously, and expertise in building, customizing, and running Generative AI.
We are now partnering on a new generative AI project called Project Helix, a joint initiative between Dell and NVIDIA, to bring Generative AI to the world’s enterprise data centers. Project Helix is a full-stack solution that enables enterprises to create and run custom AI models built with the knowledge of their business.
 Dell is designing extremely scalable, highly efficient infrastructure solutions that allows enterprises everywhere to create a new wave of generative AI solutions that will reinvent their industries and offer a competitive advantage.
Dell is designing extremely scalable, highly efficient infrastructure solutions that allows enterprises everywhere to create a new wave of generative AI solutions that will reinvent their industries and offer a competitive advantage.
The complete announcement and white paper is available here
Unpacking Project Helix
In our upcoming blog series, we will explore the world of Generative AI and LLMs, including training and fine-tuning models, reinforcement learning, general AI training and inferencing.
Ultimately, this series aims to provide an overview of the key concepts involved in AI model development and usage, specifically focusing on LLMs, their applications and, how Dell Technologies can enable you to succeed.
Part 1: Generative AI and LLMs – Introduction and Key Concepts (Transformers and training types)
We will explore the Key concept of LLM’s and GPT’s, the Transformer. What makes up a transformer architecture, why this architecture has been a game changer, along with business and technical challenges to be aware of.
Part 2: LLM Training Types and Techniques
We will focus on the training of LLMs, including the different types of training available and the tools and techniques used to create these models. We will explore how training data is collected and processed, and the importance of fine-tuning LLMs for specific tasks.
Part 3: Pre-Trained Model Fine Tuning and Transfer Learning (working with a pre-trained model)
We will delve into the world of reinforcement learning, a type of machine learning that involves training models to make decisions based on rewards or penalties. We will discuss how reinforcement learning can be used to optimize operations and improve decision-making processes in industries such as healthcare and finance.
Part 4: Inferencing
We will discuss the general training and inferencing of AI models.
Part 5: Project Helix – An Overview
We will explore the particular advantages that Dell and NVIDIA bring to the table and how this will enable enterprises to use purpose-built Generative AI on-premises to solve specific business challenges.
- How project Helix can deliver full-stack Generative AI solutions built on the best of Dell infrastructure and software, in combination with the latest NVIDIA accelerators, AI software, and AI expertise.
- Enable enterprises to use purpose-built Generative AI on-premises to solve specific business challenges.
- Assist enterprises with the entire Generative AI lifecycle, from infrastructure provisioning, large model training, pre-trained model fine-tuning, multi-site model deployment, and large model inferencing.
- Ensure security and privacy of sensitive and proprietary company data, as well as compliance with government regulations.
- Include the ability to develop safer and more trustworthy AI – a fundamental requirement of Enterprises today.
Explore Dell’s Generative AI Offerings:
- Dell’s Generative AI Services
- Dell’s Artificial Intelligence Solutions Portfolio (Including Generative AI)
- Dell’s Generative AI Solutions White Paper
- Dell’s Generative AI Inferencing Design Guide
Check Out the Generative AI 101 Blog Series:
Blogs Coming Up Next:
- Generative AI 101 Part 2: How are LLM’s Trained?
- Generative AI 101 Part 3: Pre-Trained Model Fine Tuning and Transfer Learning
- Generative AI 101 Part 4: Inferencing (Running your LLM)
- Generative AI 101 Part 5: Project Helix Dell and NVIDIA Solution Architecture


5 thoughts on “Announcing Dell Technologies Generative AI Solutions”